Checking if nodes already exist
In create tasks, you can configure Workbench to query Drupal to determine if a node exists, using the values in a specified field (referred to as the "lookup field" below) in your input CSV, such as field_local_identifier. If Workbench finds a node with a matching value in that field, it will skip to the next CSV row and not create the duplicate node.
This feature is useful if you create a subset of items as a test or quality assurance step before loading all items in your CSV, possibly using the csv_rows_to_process configuration setting. Another situation this might be useful in is if some of the nodes represented in your CSV failed to be created, you can fix the problems with those rows and simply rerun the entire batch without having to worry about removing the successful rows.
Warning
For this to work, the values in the lookup field need to be unique to each node. In other words, two more more nodes should not have the same value in this field.
Another assumption Workbench makes is that the values do not contain any spaces. They can however contain underscores, hyphens, and colons.
Note
If you are using the configuration described in "Adding children to nodes that already exist", Workbench can't reliably check if child/page nodes corrsponding to files in an input directory already exist. Follow advice provided on that page to prevent duplicate child/page nodes from being added, not the configurations described on this page.
Creating the required View
To use this feature, you first need to create a View that Workbench will query. This might seem like a lot of setup, but you can probably use the same View (and corresponding Workbench configuration, as illustrated below) over time for many create tasks.
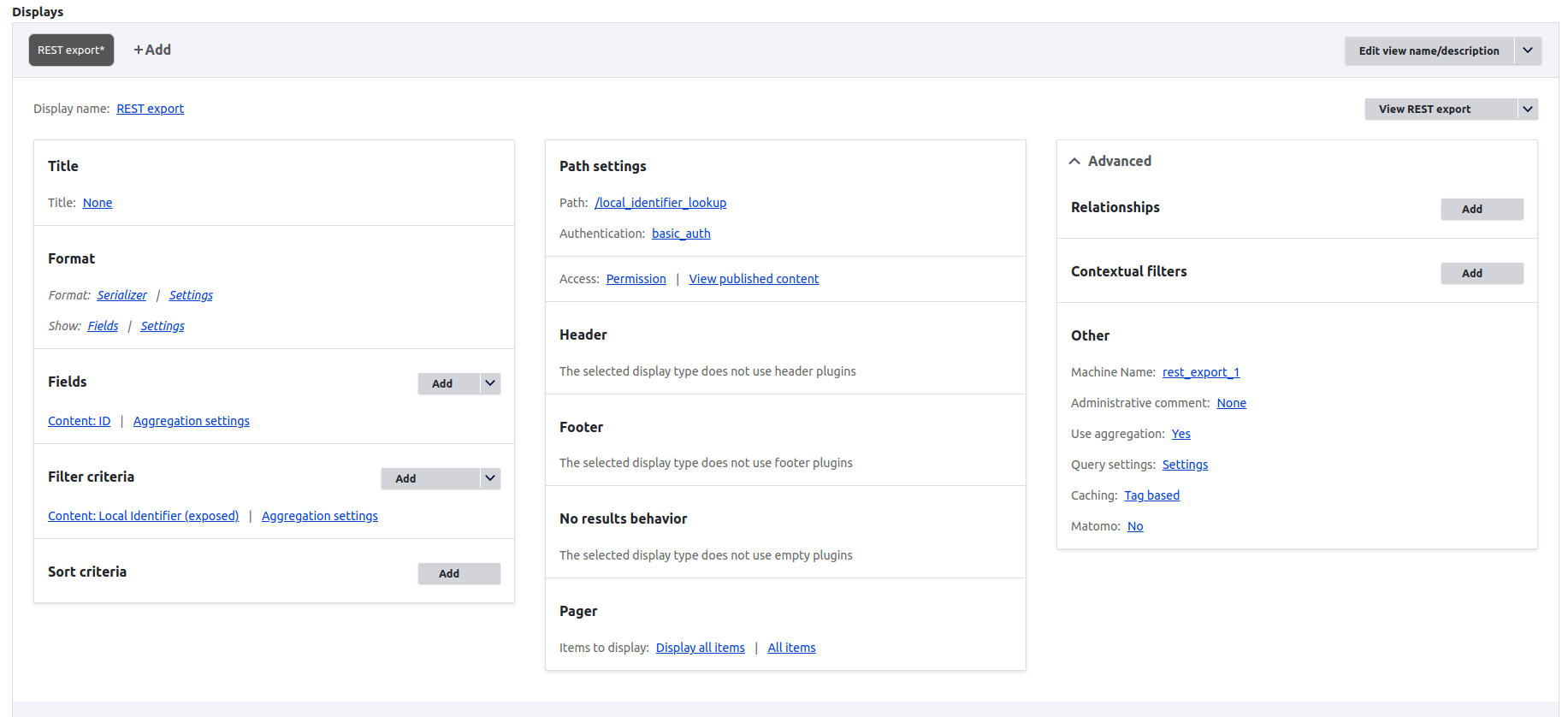
- Create a new "Content" View that has a REST Export display (no other display types are needed).
- In the Format configuration, choose "Serializer" and under Settings, check the "Force using fields" box and the "json" format.
- In the Fields configuration, choose "Content: ID" (i.e., the node ID).
- Go to the Other configuration (on the right side of the View configuration) and in the Use Aggregation configuration, choose "Yes". If asked for "Aggregation type", select "Group results together".
- In the Filter criteria configuration, add the field in your content type that you want to use as the lookup field, e.g. Local Identifier.
- Check "Expose this filter".
- Choose "Single filter".
- In the Operator configuration, select "Is equal to" and in the Value field, enter the machine name of your field (e.g.
field_local_identifier) - In the Filter identifier section, enter the name of the URL parameter requests to this View will use to identify the CSV values. You should use the same string that you used in Operator configuration (which is also the same as your field's machine name), e.g.
field_local_identifier. - In the Path settings, provide a path, e.g.
local_identifier_lookup(do not add the leading/) - Assign this path Basic authentication.
- Access should be by Permission > View published content.
- In the Pager settings, choose "Display all items". Note that in large Islandora repositories, querying this View might cause out of memory errors; if this happens to you, adding a pager to this View should help.
- Save your View.
Here is a screenshot of an example View's configuration:
If you have curl installed on your system, you can test you new REST export View:
curl -v -uadmin:password -H "Content-Type: application/json" "https://islandora.traefik.me/local_identifier_lookup?field_local_identifier=sfu_test_001"
(In this example, the REST export's "Path" is local_identifier_lookup. Immediately after the ? comes the filter identifier string configured above, with a value after the = from a node's Local Identifier field.)
If testing with curl, change the example above to incorporate your local configuration and add a known value from the lookup field. If your test is successful, the query will return a single node ID in a structure like [{"nid":"126"}]. If the query can't find any nodes, the returned data will look like []. If it finds more than one node, the structure will looks like [{"nid":"125"},{"nid":"247"}].
If you don't have curl, don't worry. --check will confirm that the configured View REST export URL is accessible and that the configured CSV column is in your input CSV.
Configuring Workbench
With the View configured and tested, you can now use this feature in Workbench by adding the following configuration block:
node_exists_verification_view_endpoint:
- field_local_identifier: /local_identifier_lookup
In this sample configuration we tell Workbench to query a View at the path /local_identifier_lookup using the filter identifer/field name field_local_identifier. Note that you can only have a single CSV field to View path configuration here. If you include more than one, only the last one is used.
Nothing special is required in the input CSV; the Workbench configuration block above is all you need to do. However, note that:
- the field you choose as your lookup field should be a regular metadata field (e.g. "Local identifier"), and not the
idfield required by Workbench. However, there is nothing preventing you from configuring Workbench (through theid_fieldsetting) to use as its ID column the same field you have configured as your lookup field. - the data in the CSV field can be multivalued. Workbench will represent the multiple values in a way that works with the "Contains any word" option in your View's Filter configuration.
- as noted above, for this feature to work, the CSV values in the lookup field cannot be used by more than one node and they cannot contain spaces.
Your CSV can look like this:
file,id,title,field_model,field_local_identifier
IMG_1410.tif,01,Small boats in Havana Harbour,Image,sfu_id_001
IMG_2549.jp2,02,Manhatten Island,Image,sfu_id_002
IMG_2940.JPG,03,Looking across Burrard Inlet,Image,sfu_id_003|special_collections:9362
IMG_2958.JPG,04,Amsterdam waterfront,Image,sfu_id_004
IMG_5083.JPG,05,Alcatraz Island,Image,sfu_id_005
Before it creates a node, Workbench will use data from the CSV column specified on the left-hand side of the node_exists_verification_view_endpoint configuration to query the corresponding View endpoint. If it finds no match, it will create the node as usual; if it finds a single match, it will skip that CSV row and log that it has done so; if it finds more than one match, it will also skip the CSV row and not create a node, and it will log that it has done this.