Creating paged, compound, and collection content
Islandora Workbench provides four ways to create paged and compound content:
- using a subdirectory structure to define the relationship between the parent item and its children
- using a subdirectory structure to define the relationship between an existing parent item and its children
- using page-level metadata in the CSV to establish that relationship
- using a secondary task.
Details on each of these methods are provided below, but here is an overview:
| Method | Use when | Parent/child relationships created by | Content types | Metadata on children | Order/weight of children |
|---|---|---|---|---|---|
| Using subdirectories | Creating paged content (or multipart content) with minimal or no metadata | Media files for children (typically page images) for each parent are grouped in subdirectories | Parents and children must have same content type | Only parent items have rows in the input CSV. Child titles are generated by page_title_template config setting; required fields in content type are inherited from parent; additional fields can be added to children using CSV value templates |
Files in a CSV row's directory are named using a "sequence indicator", which Workbench uses to populate child nodes' field_weight |
| Adding children to nodes that already exist | Creating paged content (or multipart content) with minimal or no metadata where the parent node already exists in Drupal | Media files for children (typically page images) for each parent are grouped in subdirectories | Parents and children must have same content type | Parent items have rows in the input CSV, but since parent nodes are not created, this data is only used as a basis for applying values to the children. Child titles are generated by page_title_template config setting; required fields in content type are inherited from the CSV; additional fields can be added to children using CSV value templates |
Files in a CSV row's directory are named using a "sequence indicator", which Workbench uses to populate child nodes' field_weight |
| With page/child-level metadata | Creating parents and children that have same content type, and the children have their own metadata | parent_id column in children's rows in shared CSV |
Parents and children must have same content type | All parents and children have their own rows in a single, shared input CSV | field_weight column in shared input CSV |
| Using a secondary task | Creating parents and children that have different content types, and children have their own metadata | parent_id column in children's CSV |
Parents and children can have different content types | Parents and children have separate input CSV files, with the children's file registered as the secondary task's input CSV | field_weight column in children's input CSV |
Using subdirectories
Note
Information in this section applies to all compound content, not just "paged content". That term is used here since the most common use of this method will be for creating paged content. In other words, where "page" is used below, it can be substituted with "child".
Enable this method by including paged_content_from_directories: true in your configuration file. Use this method when you are creating books, newspaper issues, or other paged content where your pages don't have their own metadata.
Another application of this method is if you have a video (for example) that you have split into multiple files. Putting all files that make up the video in a directory, and naming the the files so they will be listed in the right order, will tell Workbench to load them as children of the item described in the CSV file (i.e., the "parent" of these video "children").
CSV and directory structure
This method groups page-level files into subdirectories that correspond to each parent, and does not require (or allow) page-level metadata in the CSV file. Only the parent (book, newspaper issue, etc.) has a row on the CSV file, e.g.:
id,title,field_model
book1,How to Use Islandora Workbench like a Pro,Paged Content
book2,Using Islandora Workbench for Fun and Profit,Paged Content
Note
Unlike every other Islandora Workbench "create" configuration, the metadata CSV used when paged_content_from_directories: true is present in your config file should not contain a file column (however, you can include a directory column as described below).
This difference has a couple of important implications: 1) it assumes that the nodes described in the CSV have no media attached to them (they are simply parent containers for their children/pages) and 2) Workbench's additional_files setting does not apply when paged_content_from_directories: true is present.
If you want to attach media to the parent nodes, you will need to do so using a separate add_media task.
Each parent's pages are located in a subdirectory of the input directory that is named by default to match the value of the id field of the parent item they are pages of:
books/
├── book1
│ ├── page-001.jpg
│ ├── page-002.jpg
│ └── page-003.jpg
├── book2
│ ├── isbn-1843341778-001.jpg
│ ├── using-islandora-workbench-page-002.jpg
│ └── page-003.jpg
└── metadata.csv
If you don't want to use your id column to name the directory that stores pages, you can include a directory column in your input CSV and add the page_files_source_dir_field: directory setting to your config file. The values in the directory column can then contain the names of the page directories. If you do that, your CSV would look like this:
id,title,field_model,directory
sfu_book_1,How to Use Islandora Workbench like a Pro,Paged Content,book1
sfu_book_2,Using Islandora Workbench for Fun and Profit,Paged Content,book2
Filename conventions
The page filenames have significance. The sequence of the page is determined by the last segment of each filename before the extension, and is separated from the rest of the filename by a dash (-), although you can use another character by setting the paged_content_sequence_separator option in your configuration file. These sequence indicators are essentially physical page numbers, starting a "1" (not "0"). For example, using the filenames for "book1" above, the sequence of "page-001.jpg" is "001". Dashes (or whatever your separator character is) can exist elsewhere in filenames, since Workbench will always use the string after the last dash as the sequence number; for example, the sequence of "isbn-1843341778-001.jpg" for "book2" is also "001". Workbench takes this sequence number, strips all leading zeros, and uses it to populate the field_weight in the page nodes, so "001" becomes a weight value of 1, "002" becomes a weight value of 2, and so on. There is no need to account for pages' field_weight in your input CSV; it is automatically derived and assigned for each page based on the page's sequence number.
Important things to note when using this method:
- To use this method of creating paged content, you must include
paged_content_page_model_tidin your configuration file and set it to your Islandora's term ID for the "Page" term in the Islandora Models vocabulary (or tohttp://id.loc.gov/ontologies/bibframe/part). - The Islandora model of the parent is not set automatically. You need to include a
field_modelvalue for each item in your CSV file, commonly "Paged content" or "Publication issue". - You can apply CSV value templates to paged/child items using values from their respective parents. See the "CSV value templates" documentation for more information.
- You should also include a
field_viewer_overridecolumn in your CSV. This value is applied to the parent nodes and also the page nodes. However, if you want your page nodes to have a differentfield_viewer_overridevalue than their parents, include thepaged_content_page_viewer_overridesetting in you configuration file with the desired term ID, URI, or name from the "Islandora Display" vocabulary.- Note that if you normally don't set the "Viewer override" field in your CSV but use a Context to determine how objects display, you should not include a
field_viewer_overridecolumn in your CSV file.
- Note that if you normally don't set the "Viewer override" field in your CSV but use a Context to determine how objects display, you should not include a
idcan be defined as another field name using theid_fieldconfiguration option. If you do define a different ID field using theid_fieldoption, creating the parent/paged item relationships will still work.- The Drupal content type for page nodes is inherited from the parent, unless you specify a different content type in the
paged_content_page_content_typesetting in your configuration file. - If your page directories contain files other than page images, you need to include the
paged_content_image_file_extensionsetting in your configuration. Otherwise, Workbench can't tell which files to create pages from. - If you don't want to use your
idcolumn to name the directories that contain each item's pages, you can includepage_files_source_dir_field: directoryto your config file and add adirectorycolumn to your input CSV to name the directories. - If a sequence indicator is not an integer greater than 0 (which is a constraint of
field_weight), the page node will be created but itsfield_weightwill not be populated. An entry in your Workbench log will document this.
Controlling page weights via configuration
As explained above, page sequence indicators can serve two purposes: 1) as page numbers in page titles and 2) as values for each page's field_weight. Most people simply increment the sequence indicators by 1 (e.g., -105, -106, -107) to reflect normal page numbering. But if you discover after ingesting a book that you missed some pages and want to fix that by inserting the missing pages, you have a problem: your page numbers and weight values based on incremented-by-1 sequence indicators starting at where you inserted the missing pages will need to be updated to retain the expected sequence order.
Ingesting books with field_weight values that are incremented by more than 1 is useful because it prevents the problem of having to update field_weight values should you need to insert missing pages later because the space between two consecutive values will allow you to assign field_weight values for the new pages that fit in between the existing values without having to update succeeding field_weight values.
To assist with creating spaced-out field_weight values, Workbench provides a configuration setting, paged_content_page_weight_multiplier. Using this setting, you can use sequential, incremented-by-1 sequence indicators in your page filenames, and have Workbench space out the field_weight values for you by multiplying the embedded sequence indicators and using results of that multiplication as the field_weight values. For example, if your sequence indicators are 003 and 004, by default they will be converted into field_weight values of "3" and "4" respectively. If you set paged_content_page_weight_multiplier: 10, Workbench will populate the nodes' field_weight with "30" and "40" respectively. Since Drupal sorts field_weight values as integers, these multiplied values sort in the same way that the original values do. Since the field_weight values are 30 and 40, you will be able to add pages between the ones with the field_weight values 30 and 40 (for example, with a field_weight value of 35) in the future and not have to update subsquent field_weight values to retain the desired sort order.
Warning
Using the paged_content_page_weight_multiplier setting allows you to avoid updating field_weight values if you need to insert pages in the future, but if you add pages in the space between two adjacent field_weight values, you will need to update page titles if they include the incremented-by-1 sequence indicator as the page number.
Applying field data to pages/children created from subdirectories
Titles for pages/children created from subdirectories are generated automatically using the pattern parent_title + , page + sequence_number, where "parent title" is inherited from the page's parent node and "sequence number" is the page's sequence. For example, if a page's parent has the title "How to Write a Book" and its sequence number is 450, its automatically generated title will be "How to Write a Book, page 450". You can override this pattern by including the page_title_template setting in your configuration file. The value of this setting is a simple string template. The default, which generates the page title pattern described above, is '$parent_title, page $weight'. There are only two variables you can include in the template, $parent_title and $weight, although you do not need to include either one if you don't want that information appearing in your page titles.
The Islandora Model applied to all page/child nodes is the one defined in the paged_content_page_model_tid configuration setting. This model is automatically applied to all pages/children created from subdirectories.
Fields on pages/children that are configured as required in the parent and page content type are automatically inherited from the parent. No special configuration is necessary.
You can add additional (non-required field) metadata to pages/children using CSV value templates during the create task that creates the pages/children from subdirectories. CSV preprocessor scripts are also applied to pages/children.
Ingesting pages, their parents, and their "grandparents" using a single CSV file
In the "books" example above, each row in the CSV (i.e., book1, book2) describes a node with the "Paged Content" Islandora model; each of the books is the direct parent of the individual page nodes. However, in some cases, you may want to create the pages, their direct parents (each book), and a parent of the parents (let's call it a "grandparent" of the pages) at the same time, using the same Workbench job and the same input CSV. Some common use cases for this ability are:
- creating a node describing a periodical, some nodes describing issues of the periodical, and the pages of each issue, and
- creating a node describing a book series, a set of nodes describing books in the series, and page nodes for each book.
paged_content_from_directories: true in your config file tells Workbench to look in a directory containing page files for each row in your input CSV. If you want to include the pages, the immediate parent of the pages, and the grandparent of the pages in the same CSV, you can create an empty directory for the grandparent node, named after its id value like the other items in your CSV. In addition, and importantly, you also need to include a parent_id column in your CSV file to define the relationship between the grandparent and its direct children (in our example, the book nodes). The presence of the parent_id column does not have impact on the parent-child relationship between the books and their pages; that relationship is created automatically, like it is in the "books" example above.
To illustrate this, let's extend the "books" example above to include a higher-level (grandparent to the pages) node that describes the series of books used in that example. Here is the CSV with the new top-level item, and with the addition of the parent_id column to indicate that the paged content items are children of the new "book000" node:
id,parent_id,title,field_model
book000,,How-to Books: A Best-Selling Genre of Books,Compound Object
book1,book000,How to Use Islandora Workbench like a Pro,Paged Content
book2,book000,Using Islandora Workbench for Fun and Profit,Paged Content
The directory structure looks like this (note that the book000 directory should be empty since it doesn't have any pages as direct children):
books/
├── book000
├── book1
│ ├── page-001.jpg
│ ├── page-002.jpg
│ └── page-003.jpg
├── book2
│ ├── isbn-1843341778-001.jpg
│ ├── using-islandora-workbench-page-002.jpg
│ └── page-003.jpg
└── metadata.csv
Workbench will warn you that the book000 directory is empty, but that's OK - it will look for, but not find, any pages for that item. The node corresponding to that directory will be created as expected, and values in the parent_id column will ensure that the intended hierarchical relationship between "book000" and its child items (the book nodes) is created.
Ingesting OCR (and other) files with page images
You can tell Workbench to add OCR and other media related to page images when using the "Using subdirectories" method of creating paged content. To do this, add the OCR files to your subdirectories, using the base filenames of each page image plus an extension like .txt:
books/
├── book1
│ ├── page-001.jpg
│ ├── page-001.txt
│ ├── page-002.jpg
│ ├── page-002.txt
│ ├── page-003.txt
│ └── page-003.jpg
├── book2
│ ├── isbn-1843341778-001.jpg
│ ├── isbn-1843341778-001.txt
│ ├── using-islandora-workbench-page-002.jpg
│ ├── using-islandora-workbench-page-002.txt
│ ├── page-003.txt
│ └── page-003.jpg
└── metadata.csv
Then, add the following settings to your configuration file:
paged_content_from_directories: true(as described above)paged_content_page_model_tid(as described above)paged_content_image_file_extension: this is the file extension, without the leading., of the page images, for exampletif,jpg, etc.paged_content_additional_page_media: this is a list of mappings from Media Use term IDs or URIs to the file extensions of the OCR or other files you are ingesting. See the example below.
An example configuration is:
task: create
host: https://islandora.dev
username: admin
password: password
input_dir: input_data/paged_content_example
standalone_media_url: true
paged_content_from_directories: true
paged_content_page_model_tid: http://id.loc.gov/ontologies/bibframe/part
paged_content_image_file_extension: jpg
paged_content_additional_page_media:
- http://pcdm.org/use#ExtractedText: txt
You can add multiple additional files (for example, OCR and hOCR) if you provide a Media Use term-to-file-extension mapping for each type of file:
paged_content_additional_page_media:
- http://pcdm.org/use#ExtractedText: txt
- https://discoverygarden.ca/use#hocr: hocr
You can also use your Drupal's numeric Media Use term IDs in the mappings, like:
paged_content_additional_page_media:
- 354: txt
- 429: hocr
Note
Using hOCR media for Islandora paged content nodes may not be configured on your Islandora repository; hOCR and the corresponding URI are used here as an example only.
In this case, Workbench looks for files with the extensions txt and hocr and creates media for them with respective mapped Media Use terms. The paged content input directory would look like this:
books/
├── book1
│ ├── page-001.jpg
│ ├── page-001.txt
│ ├── page-001.hocr
│ ├── page-002.jpg
│ ├── page-002.txt
│ ├── page-002.hocr
│ ├── page-003.txt
│ ├── page-003.hocr
│ └── page-003.jpg
Warning
It is important to temporarily disable actions in Contexts that generate media/derivatives that would conflict with additional media you are adding using the method described here. For example, if you are adding OCR files, in the "Page Derivatives" Context listed at /admin/structure/context, disable the "Extract text from PDF or image" action prior to running Workbench, and be sure to re-enable it afterwards. If you do not do this, the OCR media added by Workbench will get overwritten with the one that Islandora generates using the "Extract text from PDF or image" action.
Ignoring files in page directories
Sometimes files such as "Thumbs.db" (on Windows) can creep into page directories. You can tell Workbench to ignore specific files within directories by including the paged_content_ignore_files configuration setting in your config file. Note that the default setting is to ignore "Thumbs.db" files. If you want to add additional files, or override that default setting, include the paged_content_ignore_files followed by a list of filenames and/or filename patterns that use the * wildcard, e.g.:
paged_content_ignore_files: ["Thumbs.db", "scanning_manifest.txt", "*.xml", "images.*"]
The asterisk wildcards act as you would expect: *.xml will match on "manifest.xml", "list.xml", etc., and package.* will match "package.txt" and "package.db", etc. The * wildcard can only stand for entire filenames or extensions; in other words, you cannot use a wildcard in the middle of a filename.
Note that Workbench converts all filenames (and wildcard entries) in the directories and filenames listed in the paged_content_ignore_files setting to lower case before checking to see if they are in this list. For example, if Workbench encounters a filename Scanning_Manifest.TXT, it will match "scanning_manifest.txt" in the configuration above configuration.
Workbench ignores all subdirectories within page directories.
Adding children to nodes that already exist
The preceding documentation explains how to create pages/children from the contents of subdirectories at the same time as the parent node is being created from a row in the input CSV.
The documentation in this section applies to creating pages/children from the contents of subdirectories if the parent node already exists. A use case for doing this is replacing the PDF attached to a Digital Document node with individual page nodes. Another situation where this method is useful is adding additional children to an existing Paged Content or Compound node.
In general, the configuration settings and input data structures described above apply in this situation, except for one difference in the configuration file and one difference in the input CSV:
- Your configuration file must contain
paged_content_from_directories_parents_exist: trueinstead ofpaged_content_from_directories: trueas above (notice the "parents_exist" at the end of this setting name). All other configuration settings work the same as described above. - Your input CSV must contain a
field_member_ofcolumn identifying the existing parent that the files in each directory are to be attached to as children.
A sample input CSV is:
id,field_identifier,directory,field_member_of,title,file,field_edtf_date
row_1,example_01,parent_1_files_1,4037,A sample parent that exists,,2023-01-01
row_2,example_02,parent_2_files,4182,Another existing parent,,1999-12-31
Fields in the input CSV are the basis for field values applied to each row's children, following the process described in the "Applying field data to pages/children created from subdirectories" section above. title is always a required field in create tasks. In this example CSV file and configuration, field_identifier is used to assign identifiers to the new children using a CSV value template. field_edtf_date is also included to illustrate an optional field that is applied to the children using a CSV value template. Fields in an input CSV that are optional and not configured in field templates, CSV templates, or in csv_value_templates_for_paged_content will be ignored.
There is no need to account for children/pages' field_weight in your input CSV; it is automatically derived from filenames as described below.
An accompanying sample configuration file is:
task: create
host: https://islandora.dev
username: admin
password: password
# Required.
paged_content_from_directories_parents_exist: true
# Required, as when using paged_content_from_directories.
paged_content_page_model_tid: http://id.loc.gov/ontologies/bibframe/part
input_csv: parents_exist.csv
input_dir: input_data/parents_exist
allow_missing_files: true
page_files_source_dir_field: directory
# In this type of task, CSV field templates apply to the children being created, not the existing parent.
csv_field_templates:
- field_model: http://id.loc.gov/ontologies/bibframe/part
page_title_template: '$parent_title, side $weight'
# In this type of task, csv_field_templates and csv_value_templates_for_paged_content
# both do the same thing.
csv_value_templates_for_paged_content:
- field_edtf_date: $csv_value
- field_identifier: $csv_value-$weight
Running this configuration using the sample CSV file will attach a Page model node for each file in the directory to the parent identified in that row's field_member_of.
Some important things to note:
paged_content_from_directories_parents_exist: trueapplies tocreatetasks only.- Using this configuration setting does not change or update the parent node identified in
field_member_of. If you need to change the model of the parent (for example in the use case mentioned above where you are replacing a multipage PDF attached to a Digital Document node with individual Page children), you should do so prior to running thecreatetask to add the new children in order to guarantee that all the required Context Actions, etc. work as expected. - If you are adding additional children from files in a directory to a parent node that already has some child nodes attached to it, you will need to ensure that the directory only contains files for the new children you want to add. Islandora Workbench doesn't check if a child corresponding to a file already exists, even if Drupal and Workbench are configured to do so. Also note that using
paged_content_from_directories_parents_exist: truedoesn't delete existing media or children from the target parent nodes. Children to be replaced need to be deleted separately before adding their replacements. - Related to the previous point, Workbench assigns the
field_weightof children/pages directly from the sequence indicators embedded in filenames, so name your page/child files so they have a weight that is consistent with the weights of their existing siblings. For example, if the last-sorting Page node that already exists in a given parent has a weight of "20", and you are adding additional pages, the new pages' filenames should have sequence indicators of-21,-22,-23, etc., resulting in filenames likenewspaper_2001-10-03-21.tif,newspaper_2001-10-03-22.tif,newspaper_2001-10-03-23.tifin your input directory. Using these sequence indicators will add pages 21, 22, and 23 to the target newspaper issue.
With page/child-level metadata
Using this method, the metadata CSV file contains a row for every item, both parents and children. You should use this method when you are creating books, newspaper issues, or other paged or compound content where each page has its own metadata, or when you are creating compound objects of any Islandora model. The file for each page/child is named explicitly in the page/child's file column rather than being in a subdirectory. To link the pages to the parent, Workbench establishes parent/child relationships between items with a special parent_id CSV column.
Values in the parent_id column, which only apply to rows describing pages/children, are the id value of their parent. For this to work, your CSV file must contain a parent_id field plus the standard Islandora fields field_weight, field_member_of, and field_model (the role of these last three fields will be explained below). The id field is required in all CSV files used to create content, so in this case, your CSV needs both an id field and a parent_id field.
The following example illustrates how this works. Here is the raw CSV data:
id,parent_id,field_weight,file,title,field_description,field_model,field_member_of
001,,,,Postcard 1,The first postcard,28,197
003,001,1,image456.jpg,Front of postcard 1,The first postcard's front,29,
004,001,2,image389.jpg,Back of postcard 1,The first postcard's back,29,
002,,,,Postcard 2,The second postcard,28,197
006,002,1,image2828.jpg,Front of postcard 2,The second postcard's front,29,
007,002,2,image777.jpg,Back of postcard 2,The second postcard's back,29,
The empty cells make this CSV difficult to read. Here is the same data in a spreadsheet:

The data contains rows for two postcards (rows with id values "001" and "002") plus a back and front for each (the remaining four rows). The parent_id value for items with id values "003" and "004" is the same as the id value for item "001", which will tell Workbench to make both of those items children of item "001"; the parent_id value for items with id values "006" and "007" is the same as the id value for item "002", which will tell Workbench to make both of those items children of the item "002". We can't populate field_member_of for the child pages in our CSV because we won't have node IDs for the parents until they are created as part of the same batch as the children.
In this example, the rows for our postcard objects have empty parent_id, field_weight, and file columns because our postcards are not children of other nodes and don't have their own media. (However, the records for our postcard objects do have a value in field_member_of, which is the node ID of the "Postcards" collection that already/hypothetically exists.) Rows for the postcard front and back image objects have a value in their field_weight field, and they have values in their file column because we are creating objects that contain image media. Importantly, they have no value in their field_member_of field because the node ID of the parent isn't known when you create your CSV; instead, Islandora Workbench assigns each child's field_member_of dynamically, just after its parent node is created.
Some important things to note:
- The
parent_idcolumn can contain only a single value. In other words, values likeid_0029|id_0030won't work. If you want an item to have multiple parents, you need to use a laterupdatetask to assign additional values to the child node'sfield_member_offield. - Currently, you need to include the option
allow_missing_files: truein your configuration file when using this method to create paged/compound content. See this issue for more information. idcan be defined as another field name using theid_fieldconfiguration option. If you do define a different ID field using theid_fieldoption, creating the parent/child relationships will still work.- The values of the
idandparent_idcolumns do not have to follow any sequential pattern. Islandora Workbench treats them as simple strings and matches them on that basis, without looking for sequential relationships of any kind between the two fields. - The CSV records for children items don't need to come immediately after the record for their parent, but they do need to come after that CSV record. (
--checkwill tell you if it finds any child rows that come before their parent rows.) This is because Workbench creates nodes in the order their records are in the CSV file (top to bottom). As long as the parent node has already been created when a child node is created, the parent/child relationship via the child'sfield_member_ofwill be correct. See the next paragraph for some suggestions on planning for large ingests of paged or compound items. - Currently, you must include values in the children's
field_weightcolumn (except when creating a collection and its members at the same time; see below). It may be possible to automatically generate values for this field (see this issue). - Currently, Islandora model values (e.g. "Paged Content", "Page") are not automatically assigned. You must include the correct "Islandora Models" taxonomy term IDs in your
field_modelcolumn for all parent and child records, as you would for any other Islandora objects you are creating. Like forfield_weight, it may be possible to automatically generate values for this field (see this issue).
Since parent items (collections, book-level items, newspaper issue-level items, top-level items in compound items, etc.) need to exist in Drupal before their children can be ingested, you need to plan your "create" tasks accordingly. For example:
- If you want to use a single "create" task to ingest all the parents and children at the same time, for each compound item, the parent CSV record must come before the records for the children/pages.
- If you would rather use multiple "create" tasks, you can create all your collections first, then, in subsequent "create" tasks, use their respective node IDs in the
field_member_ofCSV column for their members. If you use a separate "create" task to create members of a single collection, you can define the value offield_member_ofin a CSV field template. - If you are ingesting a large set of books, you can ingest the book-level items first, then use their node IDs in a separate CSV for the pages of all books (each using their parent book node's node ID in their
field_member_ofcolumn). Or, you could run a separate "create" task for each book, and use a CSV field template containing afield_member_ofentry containing the book item's node ID. - For newspapers, you could create the top-level newspaper first, then use its node ID in a subsequent "create" task for both newspaper issues and pages. In this task, the
field_member_ofcolumn in rows for newspaper issues would contain the newspaper's node ID, but the rows for newspaper pages would have a blankfield_member_ofand aparent_idusing the parent issue'sidvalue.
Using a secondary task
You can configure Islandora Workbench to execute two "create" tasks - a primary and a secondary - that will result in all of the objects described in both CSV files being ingested during the same Workbench job. Parent/child relationships between items are created by referencing the row IDs in the primary task's CSV file from the secondary task's CSV file. The benefit of using this method is that each task has its own configuration file, allowing you to create children that have a different Drupal content type than their parents.
The primary task's CSV describes the parent objects, and the secondary task's CSV describes the children. The two are linked via references from children CSV's parent_id values to their parent's id values, much the same way as in the "With page/child-level metadata" method described above. The difference is that the references span CSV files. The parents and children each have their own CSV input file (and also their own configuration file). Each task is a standard Islandora Workbench "create" task, joined by one setting in the primary's configuration file, secondary_tasks, as described below.
In the following example, the top CSV file (the primary) describes the parents, and the bottom CSV file (the secondary) describes the children:
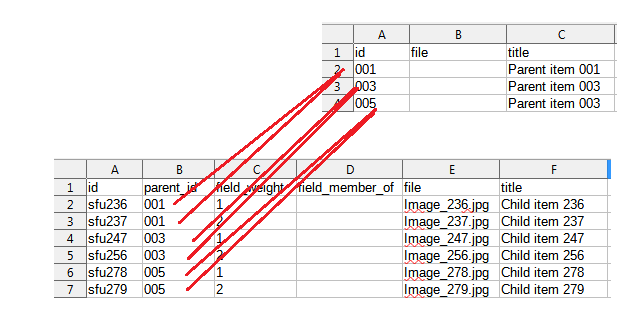
As you can see, values in the parent_id column in the secondary CSV reference values in the id column in the primary CSV: parent_id 001 in the secondary CSV matches id 001 in the primary, parent_id 003 in the secondary matches id 003 in the primary, and so on.
You configure secondary tasks by adding the secondary_tasks setting to your primary configuration file, like this:
task: create
host: "http://localhost:8000"
username: admin
password: islandora
# This is the setting that links the two configuration files together.
secondary_tasks: ['children.yml']
input_csv: parents.csv
nodes_only: true
In the secondary_tasks setting, you name the configuration file of the secondary task. The secondary task's configuration file (in this example, named "children.yml") contains no indication that it's a secondary task:
task: create
host: "http://localhost:8000"
username: admin
password: islandora
input_csv: kids.csv
csv_field_templates:
- field_model: http://purl.org/coar/resource_type/c_c513
query_csv_id_to_node_id_map_for_parents: true
Note
The CSV ID to node ID map is required in secondary create tasks. Workbench will automatically change the query_csv_id_to_node_id_map_for_parents to true, regardless of whether that setting is in your secondary task's config file.
Note
The nodes_only setting in the above example primary configuration file and the csv_field_templates setting in the secondary configuration file are not relevant to the primary/secondary task functionality; they're included to illustrate that the two configuration files can differ.
When you run Workbench, it executes the primary task first, then the secondary task. Workbench keeps track of pairs of id + node IDs created in the primary task, and during the execution of the secondary task, uses these to populate the field_member_of values in the secondary task with the node IDs corresponding to the referenced primary id values.
Some things to note about secondary tasks:
- Only "create" tasks can be used as the primary and secondary tasks.
- When you have a secondary task configured, running
--checkwill validate both tasks' configuration and input data. - The secondary CSV must contain
parent_idandfield_member_ofcolumns.field_member_ofmust be empty, since it is auto-populated by Workbench using node IDs from the newly created parent objects. If you want to assign an order to the child objects within each parent object, includefield_weightwith the appropriate values (1, 2, 3, etc., the lower numbers being earlier/higher in sort order). - If a row in the secondary task CSV does not have a
parent_idthat matches anidof a row in the primary CSV, or if there is a matching row in the primary CSV and Workbench failed to create the described node, Workbench will skip creating the child and add an entry to the log indicating it did so. - As already stated, each task has its own configuration file, which means that you can specify a
content_typevalue in your secondary configuration file that differs from thecontent_typeof the primary task. - You can include more than one secondary task in your configuration. For example,
secondary_tasks: ['first.yml', 'second.yml']will execute the primary task, then the "first.yml" secondary task, then the "second.yml" secondary task in that order. You would use multiple secondary tasks if you wanted to add children of different content types to the parent nodes.
Specifying paths to the python interpreter and to the workbench script
When using secondary tasks, there are a couple of situations where you may need to tell Workbench where the python interpreter is located, and where the "workbench" script is located.
The first is when you use a secondary task within a scheduled job (such as running Workbench via Linux's cron). Depending on how you configure the cron job, you will likely need to tell Workbench what the absolute path to the python interpreter is and what the path to the workbench script is. This is because, unless your cronjob changes into Workbench's working directory, Workbench will be looking in the wrong directory for the secondary task. The two config options you should use are:
path_to_pythonpath_to_workbench_script
An example of using these settings is (all of these settings go in the config file of the primary task):
secondary_tasks: ['children.yml']
path_to_python: '/usr/bin/python'
path_to_workbench_script: '/home/mark/islandora_workbench/workbench'
The second situation is when using a secondary task when running Workbench in Windows and "python.exe" is not in the PATH of the user running the scheduled job. Specifying the absolute path to "python.exe" will ensure that Workbench can execute the secondary task properly, like this (all of these settings go in the config file of the primary task):
secondary_tasks: ['children.yml']
path_to_python: 'c:/program files/python39/python.exe'
path_to_workbench_script: 'd:/users/mark/islandora_workbench/workbench'
Creating parent/child relationships across Workbench sessions
It is possible to use parent_id values in your CSV that refer to id values from earlier Workbench sessions. In other words, you don't need to create parents and their member/child nodes within the same Workbench job; you can create parents in an earlier job and refer to their id values in later jobs.
This is possible because during create tasks, Workbench records each newly created node ID and its corresponding value from the input CSV's id (or configured equivalent) column. It also records any values from the CSV parent_id column, if they exist. This data is stored in a simple SQLite database called the "CSV ID to node ID map".
Because this database persists across Workbench sessions, you can use id values in your input CSV's parent_id column from previously loaded CSV files. The mapping between the previously loaded parents' id values and the values in your current CSV's parent_id column are stored in the CSV ID to node ID map database.
Note
It is important to use unique values in your CSV id (or configured equivalent) column, since if duplicate ID values exist in this database, Workbench can't know which corresponding node ID to use. In this case, Workbench will create the child node, but it won't assign a parent to it. --check will inform you if this happens with messages like Warning: Query of ID map for parent ID "0002" returned multiple node IDs: (771, 772, 773, 774, 778, 779)., and your Workbench log will also document that there are duplicate IDs.
Warning
By default, Workbench only checks the CSV ID to node ID map for parent IDs created in the same session as the children. If you want to assign children to parents created in previous Workbench sessions, you need to set the query_csv_id_to_node_id_map_for_parents configuration setting to true.
Creating collections and members together
Using a variation of the "With page/child-level metadata" approach, you can create a collection node and assign members to it at the same time (i.e., in a single Workbench job). Here is a simple example CSV which shows the references from the members' parent_id field to the collections' id field:
id,parent_id,file,title,field_model,field_member_of,field_weight
1,,,A collection of animal photos,24,,
2,1,cat.jpg,Picture of a cat,25,,
3,1,dog.jpg,Picture of a dog,25,,
3,1,horse.jpg,Picture of a horse,25,,
The use of the parent_id and field_member_of fields is the same here as when creating paged or compound children. However, unlike with paged or compound objects, in this case we leave the values in field_weight empty, since Islandora collections don't use field_weight to determine order of members. Collection Views are sorted using other fields.
Warning
Creating collection nodes and member nodes using this method assumes that collection nodes and member nodes have the same Drupal content type. If your collection objects have a Drupal content type that differs from their members' content type, you need to use the "Using a secondary task" method to ingest collections and members in the same Workbench job.
Summary
The following table summarizes the different ways Workbench can be used to create parent/child relationships between nodes:
| Method | Relationships created by | field_weight | Advantage |
|---|---|---|---|
| Subdirectories | Directory structure | Do not include column in CSV; autopopulated. | Useful for creating paged content where pages don't have their own metadata. |
| Parent/child-level metadata in same CSV | References from child's parent_id to parent's id in same CSV data |
Column required; values required in child rows | Allows including parent and child metadata in same CSV. |
| Secondary task | References from parent_id in child CSV file to id in parent CSV file |
Column and values recommended in secondary (child) CSV data | Primary and secondary tasks have their own configuration and CSV files, which allows children to have a Drupal content type that differs from their parents' content type. Allows creation of parents and children in same Workbench job. |
| Collections and members together | References from child (member) parent_id fields to parent (collection) id fields in same CSV data |
Column required in CSV but must be empty (collections do not use weight to determine sort order) | Allows creation of collection and members in same Islandora Workbench job. |