Ignoring CSV rows and columns
Note
The settings documented on this page apply only to create, update, and add_media tasks. Please see this Github issue for updates.
Two exceptions are "Commenting out CSV rows" and "Ignoring CSV columns", which apply to all tasks.
Commenting out CSV rows
You can comment out rows in your input CSV, Excel file, or Google Sheet by adding a hash mark (#) as the first character of the value in the first column. Workbench ignores these rows, both when it is run with and without --check. Commenting out rows works in all tasks that use CSV data.
For example, the third row in the following CSV file is commented out:
file,id,title,field_model,field_description
IMG_1410.tif,01,Small boats in Havana Harbour,25,Taken on vacation in Cuba.
IMG_2549.jp2,02,Manhatten Island,25,Weather was windy.
#IMG_2940.JPG,03,Looking across Burrard Inlet,25,View from Deep Cove to Burnaby Mountain.
IMG_2958.JPG,04,Amsterdam waterfront,25,Amsterdam waterfront on an overcast day.
IMG_5083.JPG,05,Alcatraz Island,25,"Taken from Fisherman's Wharf, San Francisco."
Since column order doesn't matter to Workbench, the same row is commented out in both the previous example and in this one:
id,file,title,field_model,field_description
01,IMG_1410.tif,Small boats in Havana Harbour,25,Taken on vacation in Cuba.
02,IMG_2549.jp2,Manhatten Island,25,Weather was windy.
# 03,IMG_2940.JPG,Looking across Burrard Inlet,25,View from Deep Cove to Burnaby Mountain.
04,IMG_2958.JPG,Amsterdam waterfront,25,Amsterdam waterfront on an overcast day.
05,IMG_5083.JPG,Alcatraz Island,25,"Taken from Fisherman's Wharf, San Francisco."
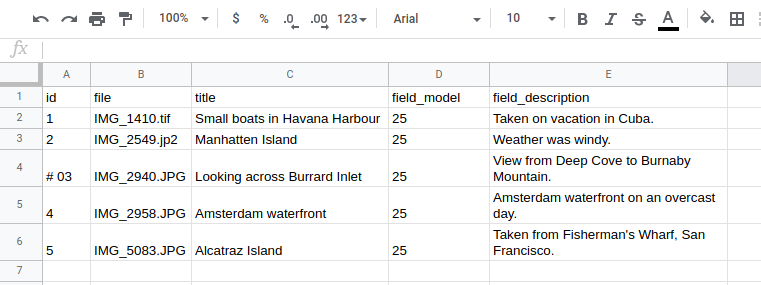
Commenting works the same with in Excel and Google Sheets. Here is the CSV file used above in a Google Sheet:
You can also use commenting to include actual comments in your CSV/Google Sheet/Excel file:
id,file,title,field_model,field_description
01,IMG_1410.tif,Small boats in Havana Harbour,25,Taken on vacation in Cuba.
02,IMG_2549.jp2,Manhatten Island,25,Weather was windy.
# Let's not load the following record right now.
# 03,IMG_2940.JPG,Looking across Burrard Inlet,25,View from Deep Cove to Burnaby Mountain.
04,IMG_2958.JPG,Amsterdam waterfront,25,Amsterdam waterfront on an overcast day.
05,IMG_5083.JPG,Alcatraz Island,25,"Taken from Fisherman's Wharf, San Francisco."
Using CSV row ranges
Workbench allows you to specify a range of contiguous CSV rows to either include or exclude during processing.
Specifying rows to process
In create and update tasks, you can use the csv_start_row and csv_stop_row configuration settings to tell Workbench to only process a specific subset of input CSV records. These settings apply when using text CSV, Google Sheets, or Excel input files. Each setting takes as its value a row number (ignoring the header row). For example, row number 2 is the second row of data after the CSV header row. Below are some example configurations.
Process CSV rows 10 to the end of the CSV file (ignoring rows 1-9):
csv_start_row: 10
Process only CSV rows 10-15 (ignoring all other rows):
csv_start_row: 10
csv_stop_row: 15
Process CSV from the start of the file to row 20 (ignoring rows 21 and higher):
csv_stop_row: 20
If you only want to process a single row, use its position in the CSV for both csv_start_row or csv_stop_row (for example, to only process row 100):
csv_start_row: 100
csv_stop_row: 100
Note
When the csv_start_row or csv_stop_row options are in use, Workbench will display a message similar to the following when run indicating the row number and the value from its ID field:
Using a subset of the input CSV (will start at row 10 / row ID scm_4587, stop at row 15 / row ID 4976).
Specifying rows to skip
Whereas csv_start_row and csv_stop_row tell Workbench to process a specific continguous subset of input CSV records, csv_start_row_skip and csv_stop_row_skip tell it to skip a contiguous subset of rows. With an input CSV like this:
field_identifier,file,title
example_id_01,,Row range example item 1
example_id_02,,Row range example item 2
example_id_03,,Row range example item 3
example_id_04,,Row range example item 4
example_id_05,,Row range example item 5
example_id_06,,Row range example item 6
example_id_07,,Row range example item 7
example_id_08,,Row range example item 8
example_id_9,,Row range example item 9
example_id_10,,Row range example item 10
if you want Workbench to skip rows 3, 4, and 5, you can include these settings in your config file:
csv_start_row_skip: 3
csv_stop_row_skip: 5
This has the same effect as commenting out rows 3, 4, and 5:
field_identifier,file,title
example_id_01,,Row range example item 1
example_id_02,,Row range example item 2
# example_id_03,,Row range example item 3
# example_id_04,,Row range example item 4
# example_id_05,,Row range example item 5
example_id_06,,Row range example item 6
example_id_07,,Row range example item 7
example_id_08,,Row range example item 8
example_id_9,,Row range example item 9
example_id_10,,Row range example item 10
A useful technique in create or update tasks is to test your configuration by processing a small set of rows before committing to processing your entire input CSV. You can run this test easily using a combination of csv_start_row/csv_stop_row and then, if you are satisfied with the results of your test, run the same configuration but skipping the rows you processed as part of the test by replacing those two settings with their "_skip" equivalents csv_start_row_skip/csv_stop_row_skip. First, tell Workbench to load three rows:
csv_start_row: 3
csv_stop_row: 5
python ./workbench --config mytask.yml
OK, connection to Drupal at http://islandora.traefik.me verified.
Using a subset of the input CSV (will start at row 3 / row ID "example_id_03", stop at row 5 / row ID "example_id_05").
"Create" task started using config file mytask.yml.
Node for "Row range example item 3" (record example_id_03) created at http://islandora.traefik.me/node/2160.
Node for "Row range example item 4" (record example_id_04) created at http://islandora.traefik.me/node/2161.
Node for "Row range example item 5" (record example_id_05) created at http://islandora.traefik.me/node/2162.
Then, if you are happy with the test's results, process the rest of the rows using the "_skip" equivalents:
csv_start_row_skip: 3
csv_stop_row_skip: 5
python ./workbench --config mytask.yml
OK, connection to Drupal at http://islandora.traefik.me verified.
Using a subset of the input CSV (will skip rows 3 to 5).
"Create" task started using config file mytask.yml.
Node for "Row range example item 1" (record example_id_01) created at http://islandora.traefik.me/node/2163.
Node for "Row range example item 2" (record example_id_02) created at http://islandora.traefik.me/node/2164.
Node for "Row range example item 6" (record example_id_06) created at http://islandora.traefik.me/node/2165.
Node for "Row range example item 7" (record example_id_07) created at http://islandora.traefik.me/node/2166.
Node for "Row range example item 8" (record example_id_08) created at http://islandora.traefik.me/node/2167.
Node for "Row range example item 9" (record example_id_9) created at http://islandora.traefik.me/node/2168.
Node for "Row range example item 10" (record example_id_10) created at http://islandora.traefik.me/node/2169.
Processing specific CSV rows
You can tell Workbench to process only specific rows in your CSV file (or, looked at from another perspective, to ignore all rows other than the specified ones). To do this, add the csv_rows_to_process setting to your config file with a list of "id" column values, e.g.:
csv_rows_to_process: ["test_001", "test_007", "test_103"]
This will tell Workbench to process only the CSV rows that have those values in their "id" column. This works with whatever you have configured as your "id" column header using the id_field configuration setting.
csv_rows_to_process also accepts a filename or path. This file should contain one ID value per line and does not need a column heading. For example, the following will work:
csv_rows_to_process: rows_to_test.txt
The "rows_to_test.txt" file looks like this:
113177
113178
113179
113180
113181
113219
113220
113221
Processing or ignoring rows based on field values
Workbench provides a simple mechanism to filter rows in your input CSV. For example, you can tell it to process only CSV rows that have a field_model of "Image", or fields that have a field_model of either "Image" or "Digital document". This is done using the csv_row_filters config setting, which defines a set of filters that are applied to your CSV at runtime.
There are two types of filters, is and isnot. Here is an example configuration using an is filter to reduce the input CSV to only rows that have a field_model of "Image":
csv_row_filters:
- field_model:is:Image
This example filters the CSV input to only rows that have a field_model of "Image" or "Digital document":
csv_row_filters:
- field_model:is:Image
- field_model:is:Digital document
Multiple filters are ORed together, i.e. in the above example, the row in kept in the input if its field_model is either "Image" or "Digital document".
isnot filters work similarly, but they exclude rows that match (is filters include rows that match). For example,
csv_row_filters:
- field_model:isnot:Image
will filter out rows that have a field_model of "Image".
Some things to keep in mind when using CSV row filters:
- You can filter on any column in your input CSV, not just
field_modelas used in examples above. - You can use filters on multivalued fields; Workbench will check each value in the field against each filter.
- You can add as many filters as you want (both
isandisnot) but as the number of filters increases, the contents of your resulting input CSV becomes less predictable. In other words, these filters are intended for, and work best in, configurations that have a small number (e.g., one, two, or three) filters. isnotfilters are applied beforeisfilters. Withinisandisnotfilters, each filter is not necessarily applied in the order they appear in your configuration file.- Filters are applied every time you run Workbench, regardless of whether you are in
--checkmode or not.
Regardless of whether you are using CSV row filters, or any other technique of ignoring CSV rows or columns, Workbench converts your input CSV into a "preprocessed" version and uses it to perform its task. This file can be found in the temporary directory defined in your Workbench config's temp_dir setting, which by default is your computer's temporary directory. If you want to inspect this file after running --check, you can see which rows result after the filters have been applied.
Warning
Using combinations of commenting out CSV rows with #, csv_start_row, csv_stop_row, csv_rows_to_process, and csv_row_filters is valid but can lead to unpredictable results. If you are using more than one of these methods of filtering out input CSV rows, during --check Workbench will add a warning entry to your log indicating that you should inspect the preprocessed version of your input CSV (and indicate where to find that file), so you can confirm that the rows you expect to be in the file are in fact there.
Ignoring CSV columns
Islandora Workbench strictly validates the columns in the input CSV to ensure that they match Drupal field names and reserved Workbench column names. To accommodate CSV columns that do not correspond to either of those types, or to eliminate a column during testing or troubleshooting, you can tell Workbench to ignore specific columns that are present in the CSV. To do this, list the column headers in the ignore_csv_columns configuration setting. The value of this setting is a list. For example, if you want to include a date_generated column in your CSV (which is neither a Workbench reserved column or a Drupal field name), include the following in your Workbench configuration file:
ignore_csv_columns: ['date_generated']
If you want Workbench to ignore the "data_generated" column and the "field_description" columns, your configuration would look like this:
ignore_csv_columns: ['date_generated', 'field_description']
Note that if a column name is listed in the csv_field_templates setting, the value for the column defined in the template is used. In other words, the values in the CSV are ignored, but the field in Drupal is still populated using the value from the field template.